1.1 - Problem Definition
Employee Attrition Prediction problem is to predict whether an employee 'stay' or 'left' the company based on the given features such as - work-life balance, salary, work experience, promotion and other factors.
This is the type of supervised - classification problem, because the dataset contains both feature values (input - work-life balance, salary, etc.) and target value (output - attrition prediction).
Supervised Classification problems helps to predict the new data label belongs to which category depending upon the given input features.
Feature: These are input values to the model and are known for 'independent variable' because each input must be uncorrelated to each other.
Target: This is the output value or what we will be predicting when validating the data. These are known for 'dependent variable' because this output depends on feature variables.
The dataset is collected from Kaggle which is an open-source for practicing machine learning projects. With this community you can gain access to the new developments in machine learning techniques, participate in competitions, and access public models and datasets that you can use for practice or implement in your own projects.
Install Tools
Install Python and Jupyter Notebook in your local machine and write this command in command prompt to open notebook in your local machine.
# for windows
D:/ml-projects> jupyter notebookThen create a file employee_attrition_prediction.ipynb inside the notebook.
ML Workflow
For every machine learning model follows same steps of training and validating/testing the dataset.
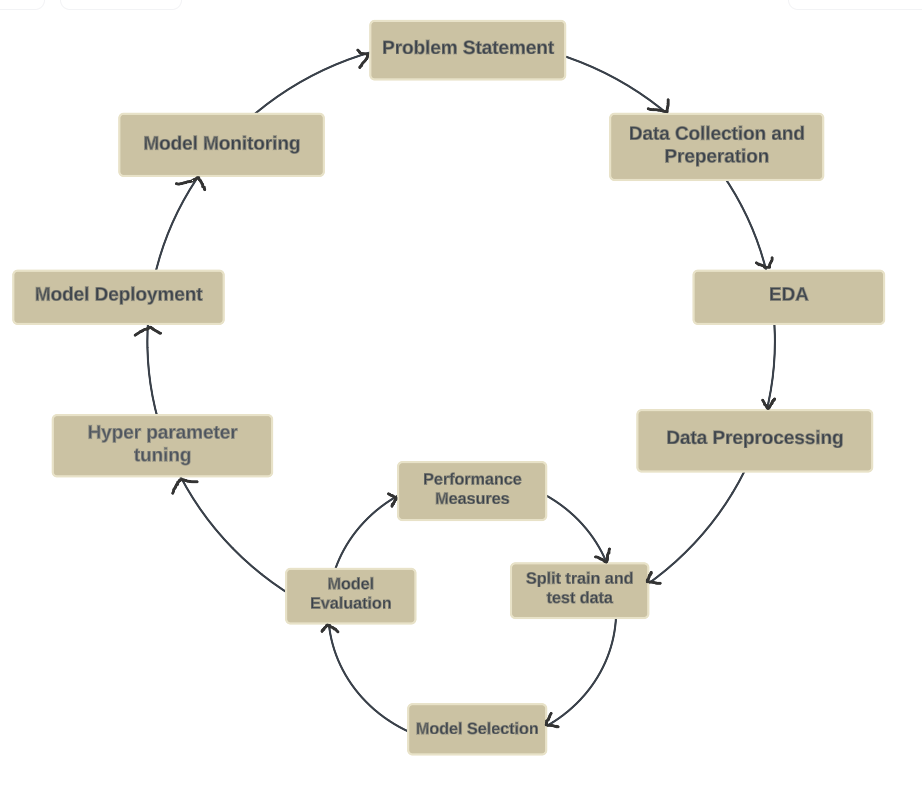
Let's discuss each steps in next lessons.