1.4 - Data Preprocessing
In this step we do data engineering.
Data Transformation
It involves converting raw data into a suitable format for analysis and machine learning. This could include changing data types, aggregating data, creating derived values, or restructuring the data.
Advantages
- Standardization: Ensure data from multiple sources is in a consistent format.
- Readiness: Prepare data for downstream processes (e.g., ML pipelines or dashboards).
- Improved Model Performance: Transforming categorical data to numerical (e.g., one-hot encoding) allows models to process the data effectively.
Let's transform our categorical data to numerical values using ordinal encoder, label encoder and one-hot encoder.
Data encoding techniques
- Ordinal encoder: Converts categorical features into integer values based on their rank or order. Example - [ 'low', medium', 'high' ]
from sklearn.preprocessing import OrdinalEncoder
# ordinal encoding for features
columns_to_encode = ['Work-Life Balance', 'Job Satisfaction', 'Performance Rating', 'Education Level', 'Job Level', 'Company Size', 'Company Reputation', 'Employee Recognition']
categories=[
['Poor', 'Fair', 'Good', 'Excellent'], # Work-Life Balance
['Low', 'Medium', 'High', 'Very High'], # Job Satisfaction
['Low', 'Below Average', 'Average', 'High'], # Performance Rating
["High School", "Bachelor’s Degree", "Master’s Degree", "Associate Degree", "PhD"], # Education Level
['Entry', 'Mid', 'Senior'], # Job Level
['Small', 'Medium', 'Large'], # Company Size
['Poor', 'Fair', 'Good', 'Excellent'], # Company Reputation
['Low', 'Medium', 'High', 'Very High'], # Employee Recognition
]
oe = OrdinalEncoder(categories=categories)
X[columns_to_encode] = oe.fit_transform(X[columns_to_encode])
- Numerical encoder: Converts directly from categorical(string) to numerical values.
# define numerical encoder
emp_bool_map = ['Overtime', 'Remote Work', 'Leadership Opportunities', 'Innovation Opportunities']
for col in emp_bool_map:
X[col] = X[col].map({'No': 0, 'Yes': 1})- Label encoder: Converts categorical text data into model-understandable numerical data without an inherent order and it is mostly used for target variables.
# label encoding for target values
y = y.map({'Stayed': 0, 'Left': 1})For practical implementation copy code till label encoder.
- One-hot encoder: Converts categorical variables into a set of binary (0 or 1) columns. E.g.: 'health-care': [0 0 1], 'IT': [0 1 0], 'education': [1 0 0].
# X = pd.get_dummies(X)
X.head()
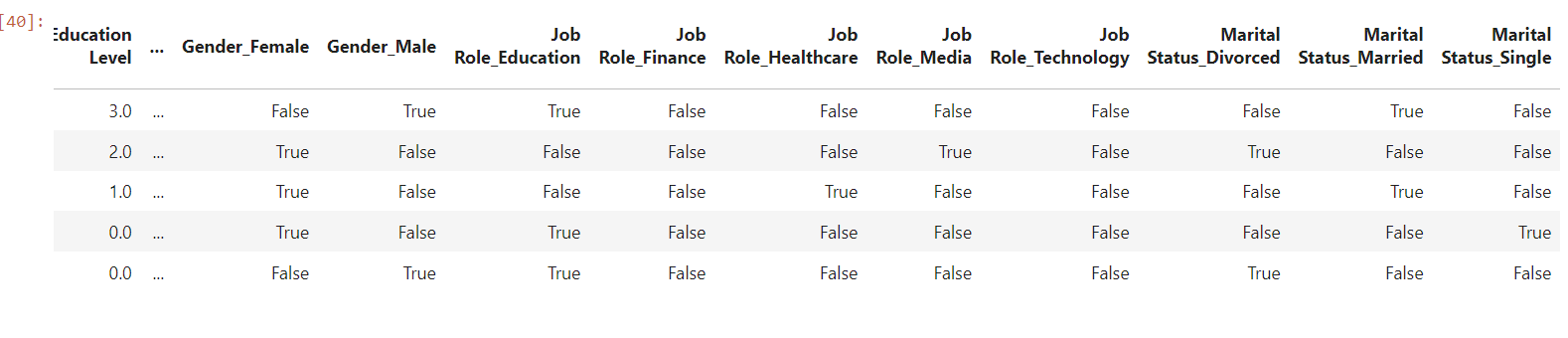
As you can see that gender, job-role and marital status are break down into gender_male, gender_female, job_role_healthcare etc... This is due to one-hot encoding, which is used when it does not have any impact to output but we want to include it in features.
We can also do feature engineering in this step, depending upon the project requirements and model performance.
Feature Engineering
The process of creating, selecting, or modifying features in a dataset to improve the predictive performance of a machine learning model.
Advantages
- Improve Predictive Power: Creating relevant features helps models better capture patterns in the data.
- Reduce Noise: Exclude irrelevant or redundant features to avoid overfitting.
- Enhance Interpretability: Features can be designed to better align with domain-specific knowledge.
Examples
- Deriving new features like "Age Group" from "Age" (e.g., <18 = 'Youth', 18-35 = 'Adult').
- Combining multiple features, such as "Annual Income" and "Family Size," to create "Income per Family Member."
- Using domain knowledge, such as calculating "BMI" from "Weight" and "Height."
X['Opportunities'] = X['Leadership Opportunities'] + X['Innovation Opportunities']
X = X.drop(columns=['Leadership Opportunities', 'Innovation Opportunities'])
X.head()
Also can change 'monthly income' to numerical encoding
# Define the function to map income ranges to ordinal values
def map_monthly_income(income):
if 1200 <= income <= 10000:
return 0
elif 10001 <= income <= 20000:
return 1
elif 20001 <= income <= 35000:
return 2
elif 35001 <= income <= 50000:
return 3
elif income >= 50001:
return 4
else:
return -1 # Handle any unexpected values
X['Monthly Income'] = X['Monthly Income'].apply(map_monthly_income)