Main Backend Setup
To setup query backend code, make sure to install following dependencies.
Install required libraries, here is the requirements.txt file,
langchain-openai
langchain_community
langchain_core
faiss-cpu
markdown
tiktoken
fastapi
pydantic
uvicorn
python-dotenv
scikit-learn
requestsInside project directory, go to venv/Scripts/activate for windows user
C:/project-directory/> venv/Scripts/activate
(venv)C:/project-directory/>cd main_backend
(venv)C:/project-directory/main_backend>Then install libraries
pip install -r requirements.txtImport libraries in app.py file,
import os
from fastapi import FastAPI, HTTPException
from fastapi.middleware.cors import CORSMiddleware
from pydantic import BaseModel
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_openai import AzureChatOpenAI
from langchain_community.document import Document
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
from langchain.memory import ConversationBufferMemory
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
from dotenv import load_dotenv
import tiktoken
import glob
The query backend service will handles the user query and orchestrates the RAG pipeline.
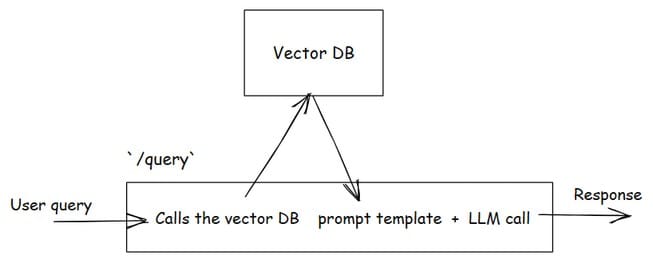
/query endpoint will accept and sends query to vector-store service (e.g.: http://localhost:8001/search ) that performs similarity search in a vector database (FAISS). This is the "retrieval" part in the pipeline,
@app.post("/query")
async def query_rag(request: QueryRequest):
try:
query = request.query
# search the docs based on query in vector-db
search_response = requests.post(f"{VECTOR_DB_URL}/search", json={"query": query})
if search_response.status_code != 200:
raise HTTPException(status_code=502, detail=f"Vector DB Error: {search_response.text}")
search_results = search_response.json()
context = "\n\n".join(doc['content'] for doc in search_results)
.....The prompt template will combine the query, context (relevant documents), chat history and instructions of how AI should behave. This is the "augmentation" part in the pipeline.
.....
prompt_template = ChatPromptTemplate.from_template(
"""
You are a helpful AI assistant that explains concepts to beginners with examples and code.
Use the provided context and chat history to answer the question. Avoid spelling mistakes.
If the context does NOT help answer the question, clearly mention that it's "out of context" and prefix your answer with a 🌟 emoji.
Chat History: {chat_history}
Context: {context}
Question: {question}
Answer:
"""
)
....Using LangChain's runnable chain, it prepares inputs, renders the prompt, sends to Azure LLM and extracts the raw text answer. This is the "generation" part in the pipeline.
....
chain = (
{
"context": lambda x: context,
"question": RunnablePassthrough(),
"chat_history": lambda x: memory.load_memory_variables({"question": x})['chat_history']
}
| prompt_template
| llm
| StrOutputParser()
)
To invoke the chain and store the current question and answer into memory.
result = chain.invoke(query)
memory.save_context({"question": query}, {"answer": result})Returns both generated answer and list of document sources.
return {
"answer": result,
"sources": [
doc['metadata']['source']
for doc in search_results if 'metadata' in doc and 'source' in doc['metadata']
],
}The main backend starts from here, lets say host is localhost and port as 8000 for local development.
if __name__ == "__main__":
uvicorn.run(app, host=HOST, port=PORT)To run the code,
C:/rag_chatbot_k8>source venv/Scripts/activate
(venv)C:/rag_chatbot_k8>cd main_backend
(venv)C:/rag_chatbot_k8/main_backend>python main.py
# or
(venv)C:/rag_chatbot_k8/main_backend>uv run main.pyNow it is running in service http://localhost:8000