Application Architecture
The DocuMancer AI Application architecture is shown below with three services: main/query backend, vector-database and batch processing backend.
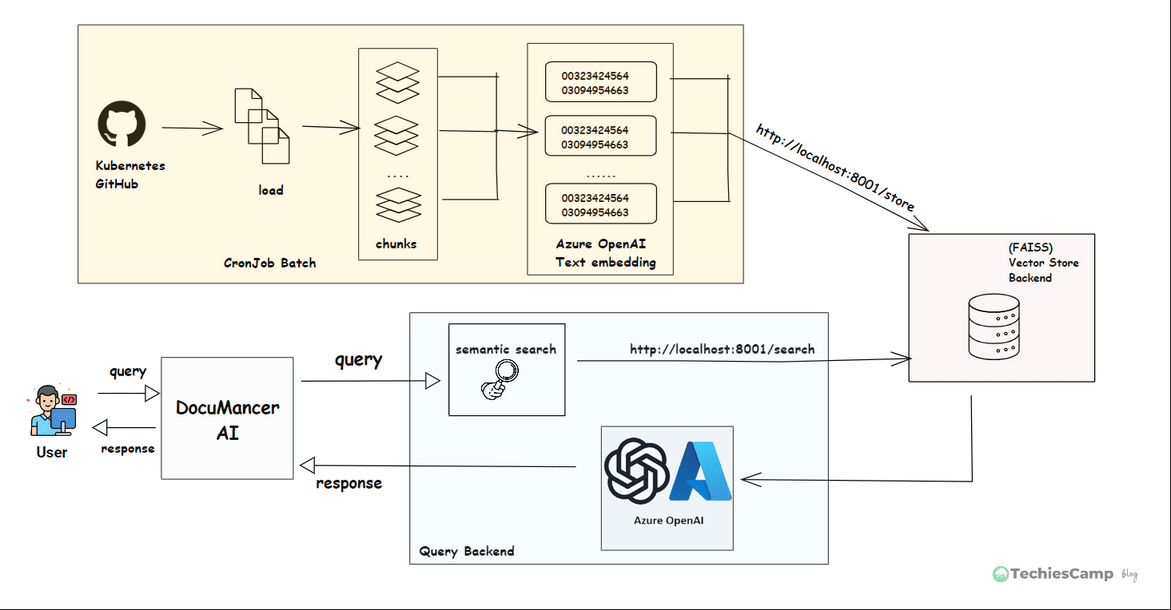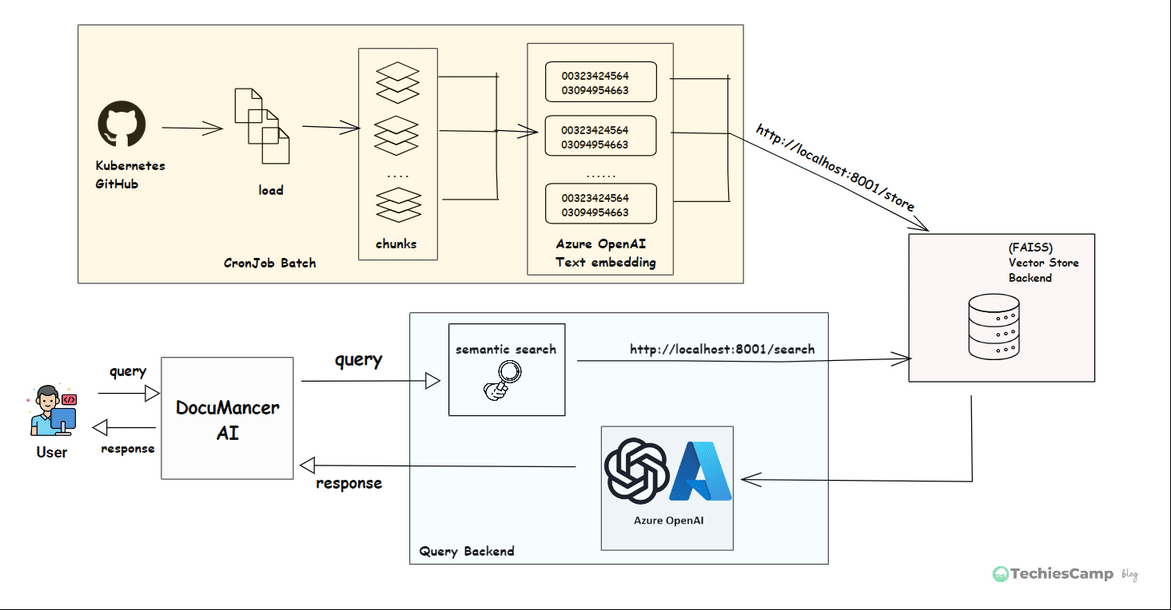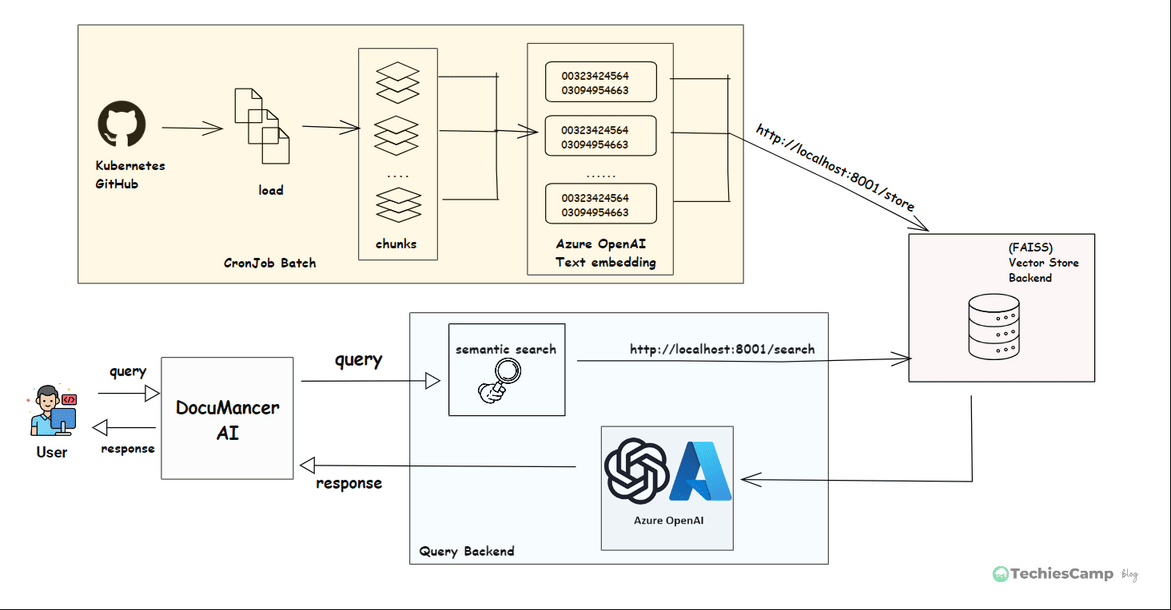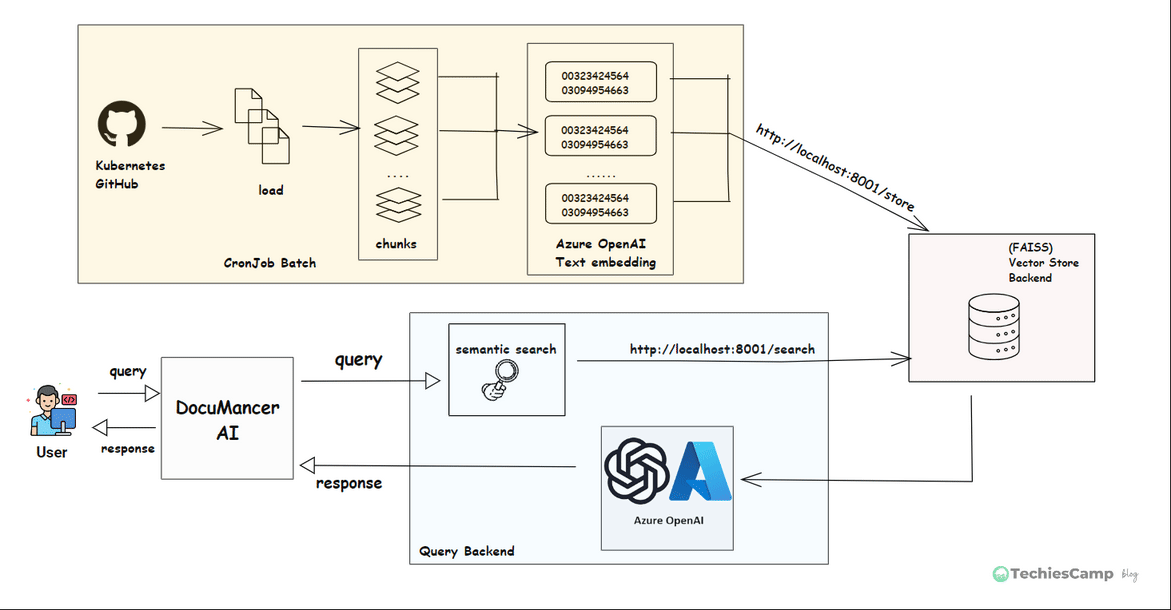
Step 1: Document Ingestion (Cron Job Batch)
A scheduled CronJob pulls .md files from Kubernetes GitHub repository. These files can be large, so we split them into smaller chunks of text. Each chunk is converted into a numerical format called "embeddings" using Azure OpenAI API (text-embedding-3-small).
We now have a small document chunks, each with a vector representing its meaning.
Step 2: Store Embeddings into Vector Database
These embeddings are stored in a special database called FAISS, which is designed for fast search. We use an API call http://localhost:8001/store to save them.
Now we can quickly search through all document chunks based on meaning.
Step 3: Generating response (Query Backend)
When user types a question in DocuMancerAI interface, the frontend UI will call Query backend server via API call http://localhost:8000/query. This query is sent to Vector Service backend for embedding the query and search in FAISS database (http://localhost:8001/search) to find the most relevant chunks of documents.
These document chunks and the original question are sent to query backend where it calls the Azure OpenAI's GPT model. The GPT reads everything and generates a an accurate, helpful answer based on real documentation.
Next section explains the development of code.