How to Build a RAG-Powered Chatbot
Here’s a simplified RAG architecture you can implement using modern, open-source tools:
Choose a Language Model (LLM)
Use open-source models like LLaMA, Mistral, or Falcon, or hosted ones like Cohere, Anthropic Claude, Open AI GPT or Azure Open AI.
Use a Text Embedding Model
Before storing anything, you’ll need to convert your documents into embeddings — a numerical representations that LLMs can "understand".
Use models from:
- OpenAI (
text-embedding-3-small, etc.) - Hugging Face Transformers
- Sentence Transformers
Set Up a Vector Store
Store and search those embeddings using efficient vector databases like:
- FAISS (Facebook AI Similarity Search)
- Pinecone (managed)
- ChromaDB (local and fast)
- Weaviate (scalable + schema-based)
These tools let you perform similarity search in milliseconds, fetching the most relevant content for any query.
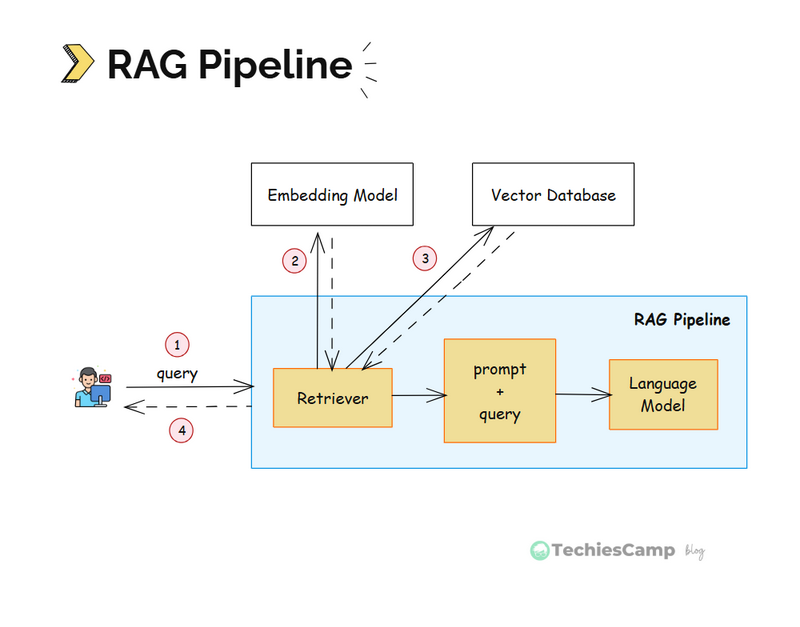
Build the Retriever
When a user submits a question, the retriever converts it into an embedding and performs a vector search to pull the most relevant document chunks from your knowledge base.
Augment and Generate the Answer
Pass both the user's query and the retrieved documents to the LLM. The model then uses this grounded context to generate a reliable, context-aware response.
Build a front-end using React, Next.js, or your preferred framework. Connect it with your backend via APIs.
Wrap It in a Chat Interface
Build your user interface using modern frameworks:
- Frontend: React, Next.js, Vue
- Backend/API: Node.js, Flask, FastAPI
Add features like streaming responses, citations, or document previews to enhance UX.
(Optional) Add Memory, Feedback, and Analytics
Take it a step further to enhance RAG chatbot:
- Chat History: Maintain session context
- Analytics: Track most-asked questions
- Feedback loops: Improve accuracy and retriever performance over time