LLM and Hugging Face: Text Generation
Text generation is one of the most fascinating applications of Large Language Models (LLMs). With models like GPT-2, GPT-Neo, and Mistral, you can generate creative, coherent, and contextually relevant text from a simple input prompt.
However, one common issue that developers face is repetitive output, where the model generates the same phrases or sentences repeatedly.
This can detract from the quality and usefulness of the generated text.
In this blog, let's explore how to set up a text generation feature using Hugging Face in a React and Node.js application.
We’ll also dive into techniques to tackle repetitive outputs and improve the quality of generated text. Let’s get started!
Text Generation with Hugging Face: Basics
Text generation involves providing a prompt to an LLM, which then generates a continuation of the text.
Here’s how you can set up a basic text generation feature in a MERN stack app.
Step-1: Backend setup code
Continue with the previous backend setup and text generation route.
// route for text generation
app.post('/api/text-generation', async(req, res) => {
const { textGen } = req.body
try {
const response = await hf.textGeneration({
model: 'gpt2',
inputs: textGen,
parameters: {
max_new_tokens: 50, // limit the length of generated text
return_full_text: false, // exclude input prompt in the output
}
})
res.status(200).send(response)
} catch(err) {
res.status(500).json({
message: `Error in generating text at backend ${err}`
})
}
})
You can use different models such as: gpt-neo, opt, or mistral (e.g., EleutherAI/gpt-neo-2.7B which provides better context and handling diversity of text. The output format for text-generation is:
output: {
generated_text: '..........'
}Step-2: Setup frontend REACT
Next, let’s create a simple React frontend to interact with the backend API.
import React, { useState } from 'react'
import axios from 'axios'
const TextGeneration = () => {
const [textGen, setTextGen] = useState({
ques: '',
isGenerated: false
})
const [result, setResult] = useState('')
const handleGenerate = async(e) => {
e.preventDefault()
try {
const response = await axios.post('http://localhost:5000/api/text-generation', { textGen: textGen.ques })
setTextGen({
...textGen,
isGenerated: true
})
setResult(response.data)
} catch(err) {
setResult(err)
}
}
return (
<div className='textGen-container'>
<h2>Text Generation</h2>
<p>{ result.message && result.message }</p>
<div className='textGen-window'>
<p className='yourQues'>{textGen.isGenerated && textGen.ques}</p>
<p className='yourResult'>{ result.generated_text && result.generated_text }</p>
</div>
<input
type='text'
value={textGen.ques}
onChange={(e) => setTextGen({ ...textGen, ques: e.target.value })}
/>
<button onClick={handleGenerate}>Generate</button>
</div>
)
}
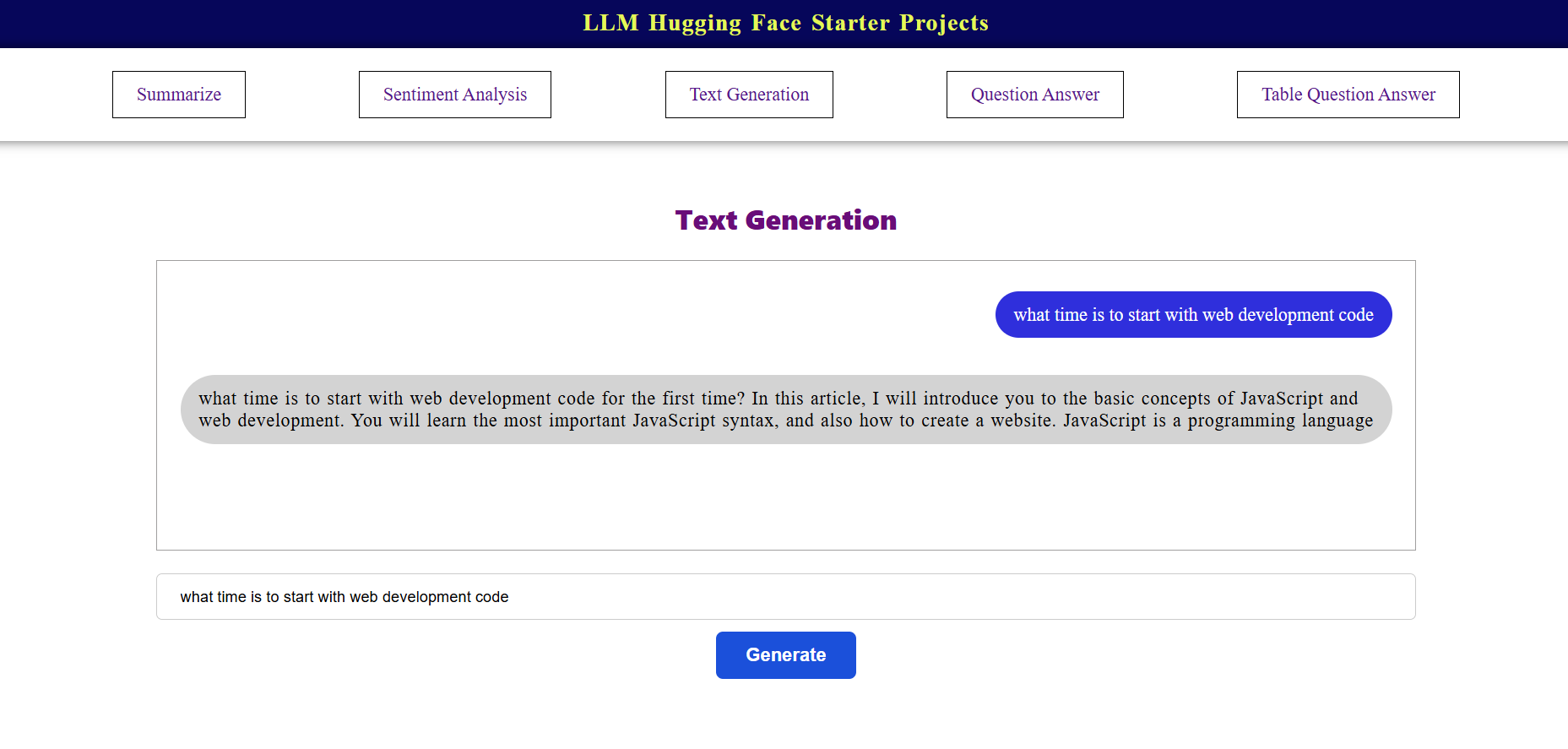
export default TextGenerationThe output renders a repetitive message as shown below:
Issue with repetitive output sentences
When using models like GPT-2, you might notice that the generated text often contains repetitive phrases or sentences. For example:
"I like to go to the park. I like to go to the park. I like to go to the park."This happens because the model tends to get stuck in a loop, especially when generating longer text or when the input prompt lacks sufficient context.
Solving Repetition: Techniques to Improve Text Generation
To address repetitive outputs, we can tweak the text generation parameters, use larger or fine-tuned models, and apply post-processing techniques.
Let’s explore these solutions in detail.
1. Adjust Text Generation Parameters
The repetitive output may result from low diversity in the text generation process. You can address this by tweaking the following parameters:
Key Parameters to Adjust
temperature: Controls randomness. Lower values (e.g., 0.4) make output more deterministic, while higher values (e.g., 0.8-1.0) increase creativity.top_p(nucleus sampling): Filters low-probability words. Typical values are 0.8-0.95 for diverse outputs.top_k: Limits the vocabulary size to the top-k most probable words. Use values like 50-100.max_new_tokens: Shorten the output if the model generates too much repetitive text.seed: Random sampling seed.return_full_text: Whether to prepend the prompt to the generated text
parameters: {
max_new_tokens: 50,
temperature: 0.7,
top_p: 0.9,
top_k: 50,
seed: 42,
return_full_text: false
}
2. Use Larger or fine-tuned model
- Larger Models: Models like
gpt-neo,opt, ormistral(e.g.,EleutherAI/gpt-neo-2.7B) often provide better context handling and diversity. - Fine-Tuned Models: Consider using a model fine-tuned for storytelling, dialogue, or more specific text generation tasks.
3. Post preprocessing the output
If repetition persists, apply a post-processing step to filter out repetitive phrases. For example:
function removeRepetitions(text) {
const sentences = text.split('. ');
const uniqueSentences = [...new Set(sentences)];
return uniqueSentences.join('. ');
}
Apply this function to response.generated_text before sending the output to the client.
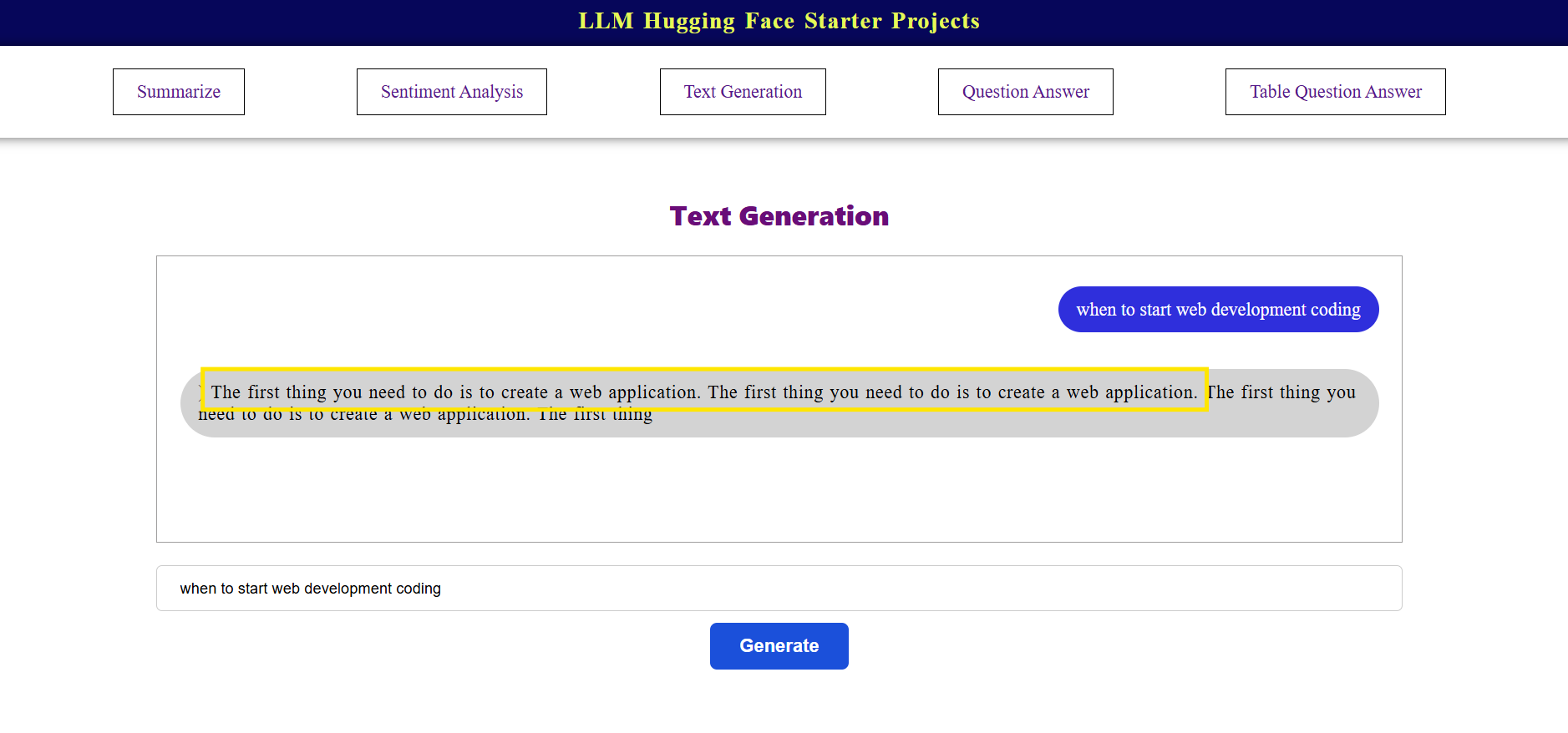
4. Enable repetition penalty
Use repetition penalty if supported by your backend API or library. This discourages the model from repeating the same phrases:
parameters: {
max_new_tokens: 50,
temperature: 0.7,
top_p: 0.9,
top_k: 50,
repetition_penalty: 1.2, // Penalize repetition (values >1.0)
seed: 42
}
5. Retry with diverse Inputs
Ensure your input (textGen) is long enough and diverse to give the model more context to work with. For example:
"I like to have a good time with my friends and family. When I am not with them, I enjoy reading books and exploring nature."
Here's how updated backend looks like:
// route for updated text-generation with parameters
app.post('/api/update/text-generation', async (req, res) => {
const { textGen } = req.body;
console.log('Input for text generation:', textGen);
// EleutherAI/gpt-neo-2.7B
try {
const response = await hf.textGeneration({
model: 'EleutherAI/gpt-neo-2.7B', // Use a larger, more diverse model if available
inputs: textGen,
parameters: {
max_new_tokens: 50,
temperature: 0.7,
top_p: 0.9,
top_k: 50,
repetition_penalty: 1.2,
seed: 42
}
});
// const generatedText = response?.generated_text || 'No text generated';
console.log('Generated text response:', response);
// Optional post-processing
const finalText = removeRepetitions(response.generated_text);
res.status(200).send({ response: finalText });
} catch (err) {
console.error('Error in text generation:', err.message);
res.status(500).json({
message: `Error in generating text at backend: ${err.message}`
});
}
});
// Utility to remove repetitions
function removeRepetitions(text) {
const sentences = text.split('. ');
const uniqueSentences = [...new Set(sentences)];
return uniqueSentences.join('. ');
}Here's the updated frontend code:
import React, { useState } from 'react'
import axios from 'axios'
const TextGeneration = () => {
const [textGen, setTextGen] = useState({
ques: '',
isGenerated: false
})
const [result, setResult] = useState('')
const handleGenerate = async(e) => {
e.preventDefault()
try {
const response = await axios.post('http://localhost:5000/api/update/text-generation', { textGen: textGen.ques })
setTextGen({
...textGen,
isGenerated: true
})
setResult(response.data.response)
}catch(err) {
setResult(err)
}
}
return (
<div className='textGen-container'>
<h2>Text Generation</h2>
<p>{ result.message && result.message }</p>
<div className='textGen-window'>
<p className='yourQues'>{textGen.isGenerated && textGen.ques}</p>
<p className='yourResult'>{ result && result }</p>
</div>
<input
type='text'
value={textGen.ques}
onChange={(e) => setTextGen({ ...textGen, ques: e.target.value })}
/>
<button onClick={handleGenerate}>Generate</button>
</div>
)
}
export default TextGenerationThe updated code output renders like the below figure.
Run the application
- Backend
// if nodemon installed
// in package.json
{
....,
"scripts": {
"start": "nodemon server.js",
----------,
}
}
// in commage prompt
npm start
// if nodemon not installed
node server.js- Frontend
npm start