MLflow workflow
Here's the workflow, that explained with detailed real-world tasks and how each component fits in.
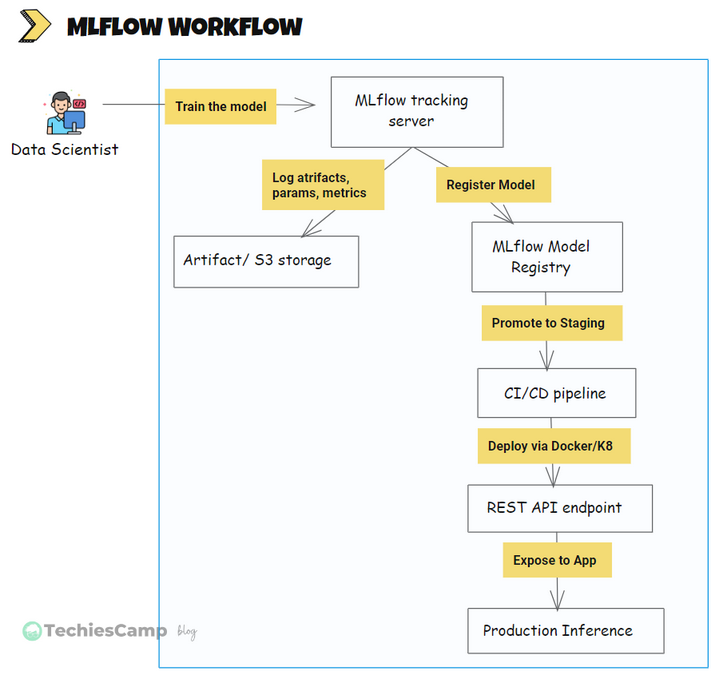
Step-1: Data Scientist Trains the Model
The Data scientist writes training code, usually in Python using Scikit-learn, PyTorch, TensorFlow etc. Adds MLflow tracking to log experiment.
import mlflow
with mlflow.start_run():
mlflow.log_param("lr", 0.01)
mlflow.log_metric("accuracy", 0.04)
mlflow.sklearn.log_model(model, "model")📌 DevOps Task:
- Ensure the MLflow client library is available via Docker/Conda envs.
- Maintain reproducible environments using version controlled
MLProjectorDockerfile
Step-2: MLflow Tracking Server Logs Everything
The MLflow server receives:
- Parameters (
lr,batch_size) - Metrics (
accuracy,loss) - Artifacts (trained model, plots)
- Source version (Git SHA, scripts)
📌 DevOps Task:
- Host MLflow Tracking Server (Docker/Kubernetes)
- Use persistent volume for backend store (Postgres, MySQL)
- Set up S3/GCS/Azure Blob for artifact storage
- Enable access control (auth proxy like OAuth2 Proxy or Keycloak)
Step-3: Artifact Store Saves Model Outputs
- Artifacts like:
- Trained model (
model.pkl,model.onnx, etc.) - Visualization (
confusion_matrix.png) - Feature importance (
feature_names.pkletc.) - Preprocessing library (
standardscaler.pkl,ordinalencoder.pkletc.)
- Trained model (
📌 DevOps Task:
- Use cloud storage buckets (e.g., AWS S3, GCP Storage)
- Automate lifecycle rules (archive older runs, retain N recent models)
Step-4: MLflow Model Registry Registers Models
- Models can be versioned and transitioned between stages:
None→Staging→Production→Archived
📌 DevOps Task:
- Automate model registration and promotion using MLflow REST APIs
- Set approval gates (manual/automated) for promoting to staging
- Trigger alerts when a new model is pushed to the registry
Step-5: CI/CD Pipeline Promotes & Deploys Models
- CI/CD pipeline triggers on:
- New model pushed to registry
- Model tagged as
Production-ready
📌 DevOps Task:
- Setup GitHub Actions/GitLab CI to:
- Pull model from registry using MLflow CLI/API
- Build Docker image with model and inference code
- Push to container registry (DockerHub/ECR)
- Deploy to staging/production on Kubernetes
- Include rollback mechanisms and blue-green deployment logic
Step-6: Model Served as REST API
- MLflow can serve models using:
mlflow models serve- Custom Flask/FastAPI server
- Or exported to platforms like SageMaker
📌 DevOps Task:
- Deploy model server as a microservice
- Add observability: request logs, prediction latency, status codes
- Secure endpoints (rate limiting, authentication)
Step-7: Expose to App for Inference
- Now the model is live — applications call it to get predictions.
POST /predict
{
"data": [5.1, 3.5, 1.4, 0.2]
}
📌 DevOps Task:
- Expose inference endpoint via API Gateway
- Monitor:
- Throughput
- Error rates
- Drift detection (data vs training distribution)
- Log inputs & outputs (with obfuscation if needed)
💡 Bonus: Automate End-to-End

You can set up the entire MLflow workflow using:
- Terraform to deploy MLflow infra (on AWS/GCP/Azure/K8s)
- Argo Workflows or Kubeflow Pipelines to orchestrate ML steps
- Prometheus + Grafana for dashboarding and alerts
- Slack/Email/Discord alerts on model promotions or failures