Unsupervised Machine learning
Explore Clustering, Association Rule and Dimensionality Reduction algorithms.
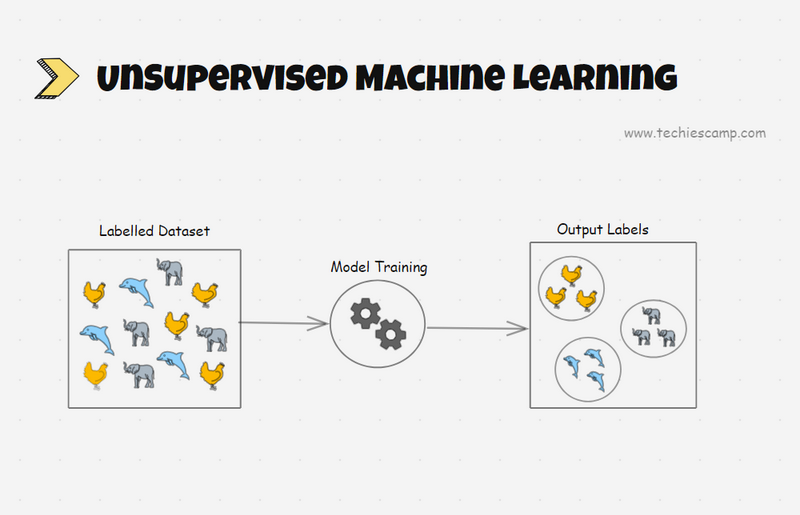
Unsupervised ML algorithms are trained on unlabeled datasets, where data points do not have corresponding labels or output values.
This type of machine learning explores the data to find patterns and structures within it.
Types of Unsupervised ML Algorithms
There are three types of algorithms in unsupervised machine learning.
1. Clustering
Group similar data points together based on their features(input in the dataset). The most commonly used algorithms are K-means clustering, and Hierarchical clustering.
Types of clustering
1. Exclusive clustering: It is the belong process of grouping one piece of data that belongs to one cluster. Also known as "hard" clustering. Algorithms used in this type are K-Means clustering.
2. Overlapping clustering: Defines that one data point can belong to more than one cluster with different degrees of belonging. Also known as "soft" clustering.
3. Hierarchical clustering: As the name suggests, it creates a hierarchy of clustered data items. To obtain clusters, data is either divided or merged based on hierarchy. There are two techniques used in hierarchical clustering, Agglomerative cluster, and Divisive cluster
4. Probabilistic clustering: Data points are clustered based on the likelihood that they belong to a particular distribution. It helps to solve density estimation or “soft” clustering problems.
Algorithms used in this type are Gaussian Mixture Models(GMM).
2. Association Rule Mining
Identify relationships between items in a dataset. They are commonly used in Market-Basket analysis (MBA) to discover patterns like "if a customer buys X, they are likely to buy Y."
The algorithms used in association rule are the Apriori Algorithm, FP-Growth algorithm, etc.
The classic example is Amazon's recommendation system where we see the "frequently bought together" section uses the Association Rule Mining algorithm.
Another example is considered a bakery shop where, let's say, there are 100 customers on Sunday morning who buy bread, cakes, and biscuits.
Let's say that 50 customers bought cakes, out of 50 customers 25 customers also bought bread with cake. The association rule here is:
- Support tells how frequently a particular item is bought. It tells the popularity of data item. If customers buy cakes, it means they will buy bread too, with the support value of 25/100 = 25% (buy both cakes + bread)
- Confidence tells likely Y item is bought when X item is bought. Here, how likely is bread will bought when cake is bought ? 25/50 = 50%
- Lift is the likelihood of item Y being purchased when item X is sold. It is the "Ratio of confidence and support value".
3. Dimensionality Reduction
Dimensionality reduction is the process of reducing the number of features in a dataset and preserving the information of the dataset as much as possible.
It is a powerful tool used in data exploratory analysis, to reduce the number of features in dataset and improves the overall performance of the model.
Algorithms used in this type of unsupervised machine learning are Principal Component analysis (PCA) and Linear Discriminant Analysis (LDA).
Principle Component Analysis (PCA)
Used to reduce the number of features in a data while preserving as much variance as possible.
For example, imagine you a closet full of clothes scattered everywhere. PCA is like finding the most important ways to organize your items.
Keeping the most useful categories (such as shirts, pants, dress etc. ) and making everything easier to understand.
Linear Discriminant Analysis (LDA)
Similar like PCA, but mainly used for supervised classification. It tries to maximize the separation between multiple classes in the data.
Suppose you have data on different types of flowers (like iris flowers dataset) with features (like petal length, petal width, etc) and flower species (like iris-setosa, iris-versicolor, iris-virginica) is the class label which we want to predict.
Using LDA, you can reduce the features to the main discriminant that best separates each flower type, making it easier for a model to classify them.
Key Differences
- PCA is unsupervised, focuses on maximizing variance in data, and doesn’t use class labels.
- LDA is supervised, and focuses on maximizing class separation by leveraging class labels.
Applications of Unsupervised ML
- Customer Segmentation: In customer segmentation, grouping of customers are based on their behavior and preferences. Common algorithms used in this type of problem are K-Means, Hierarchical cluster.
- Anomaly Detection: The main goal in this problem statement is to identifying unusual data points. The algorithms used in this type are K-Means, Hierarchical cluster.
- Market Basket Analysis: This is association rule mining based problem which is used to discover product associations to improve recommendation systems for user. Apriori Algorithm and FP-Growth are common algorithms used for this type.
- Document Clustering: This problem usually comes under Natural Language Processing (NLP) along with Clustering technique. It is to group similar documents together and some of the algorithms used for this type are K-Means, Hierarchical cluster, DBSCAN.