Kubernetes Custom Schedulers
When you deploy a pod in Kubernetes, the Kubernetes scheduler takes care of scheduling the pod to a node. This is done via the default scheduler in Kubernetes.
Is the default scheduler enough for scheduling?
For most use cases, the default scheduler is sufficient. It does a good job of distributing pods across nodes based on resource requirements, affinity/anti-affinity rules, taints and tolerations, and other built-in constraints.
However, there are use cases where you might need custom scheduling decisions due to complex business requirements where you have to implement own scheduling algorithm and logic.
Real World Example
Take an example of machine learning workload with specialized hardware requirements.
Consider a project running a Kubernetes cluster with a mix of CPU-only nodes and nodes with GPUs from different vendors (NVIDIA, AMD, etc.).
In this case, a custom scheduler could be implemented to:
- Schedule pods with specific ML frameworks to nodes with compatible GPUs
- Ensure even distribution of workloads across different GPU types.
- Consider factors like GPU memory, CUDA cores, or other specific hardware features when placing pods
- Ensure it uses the best scheduling strategy like
MostAllocatedorRequestedToCapacityRatiofor better bin packing that translates in to cost savings.
Once such example is the Volcano scheduler that provides advanced scheduling capabilities for batch and machine learning workloads.
Also, when using managed Kubernetes services like Amazon EKS, Google GKE, or Azure AKS, you generally have limited ability to modify or configure the default scheduler provided by the managed service.
However, you can still deploy and use custom schedulers to meet specific scheduling requirements
How Custom Scheduler Works in Kubernetes
A custom scheduler works by intercepting pods before they are scheduled by the default scheduler.
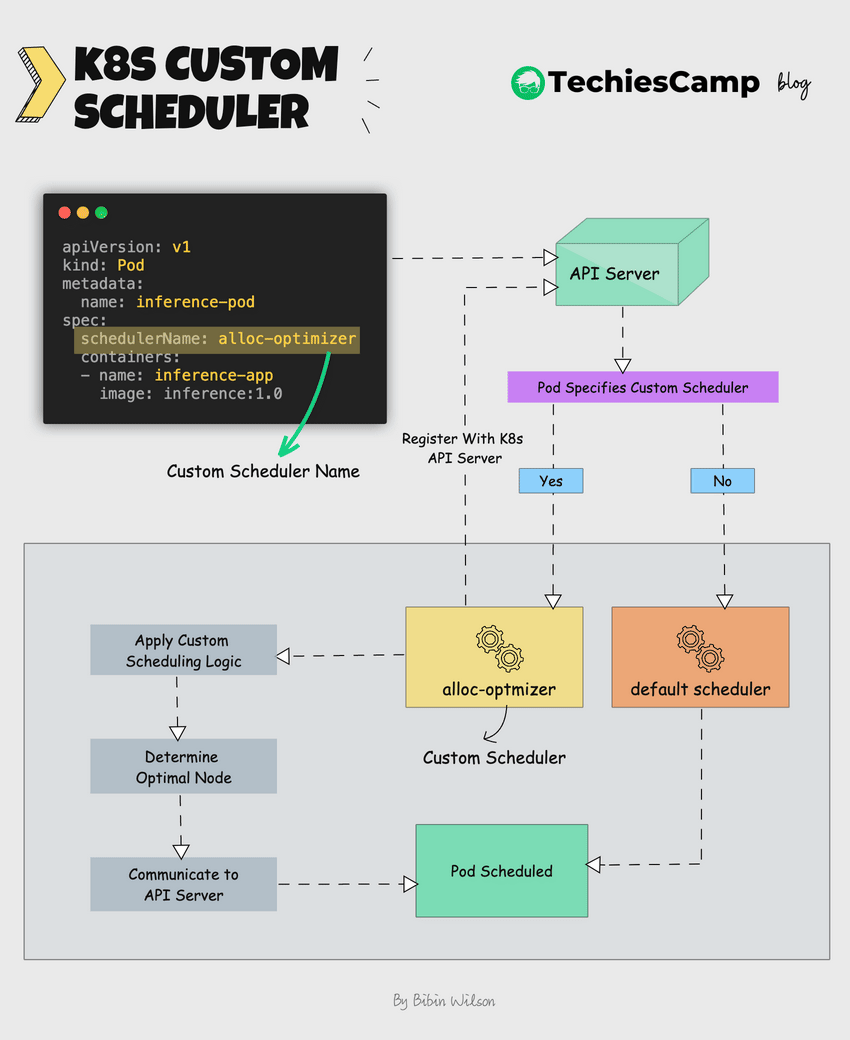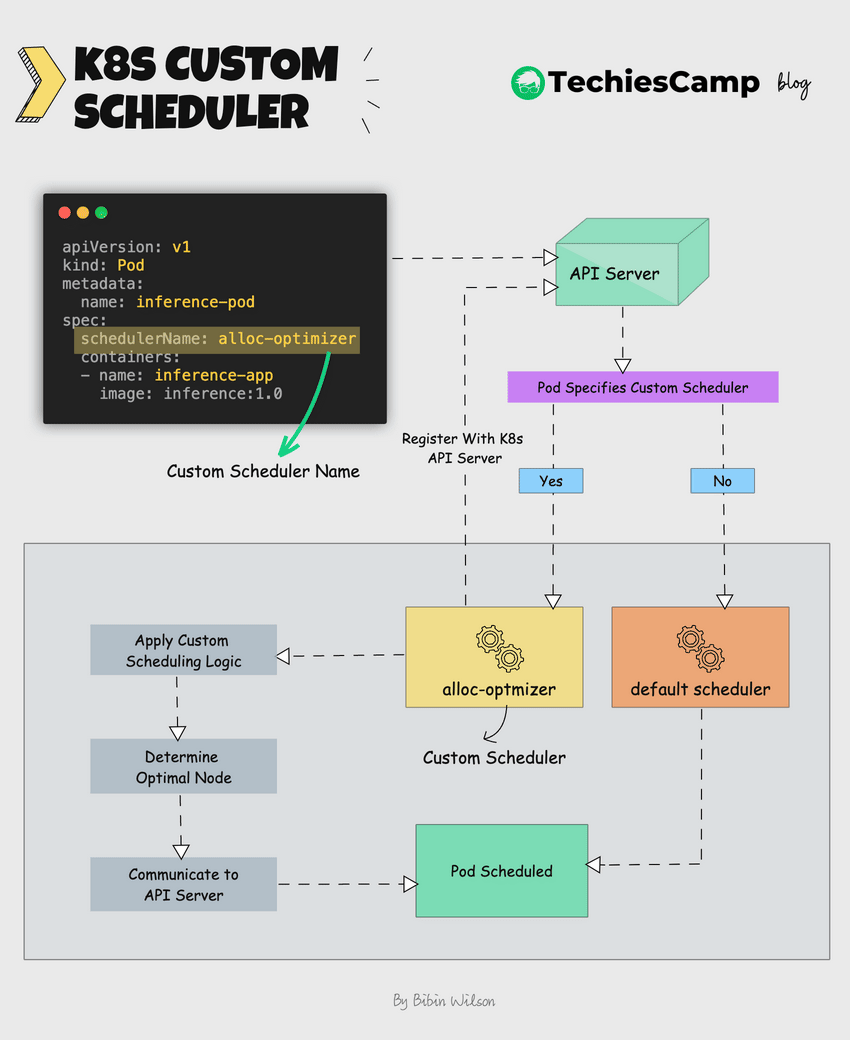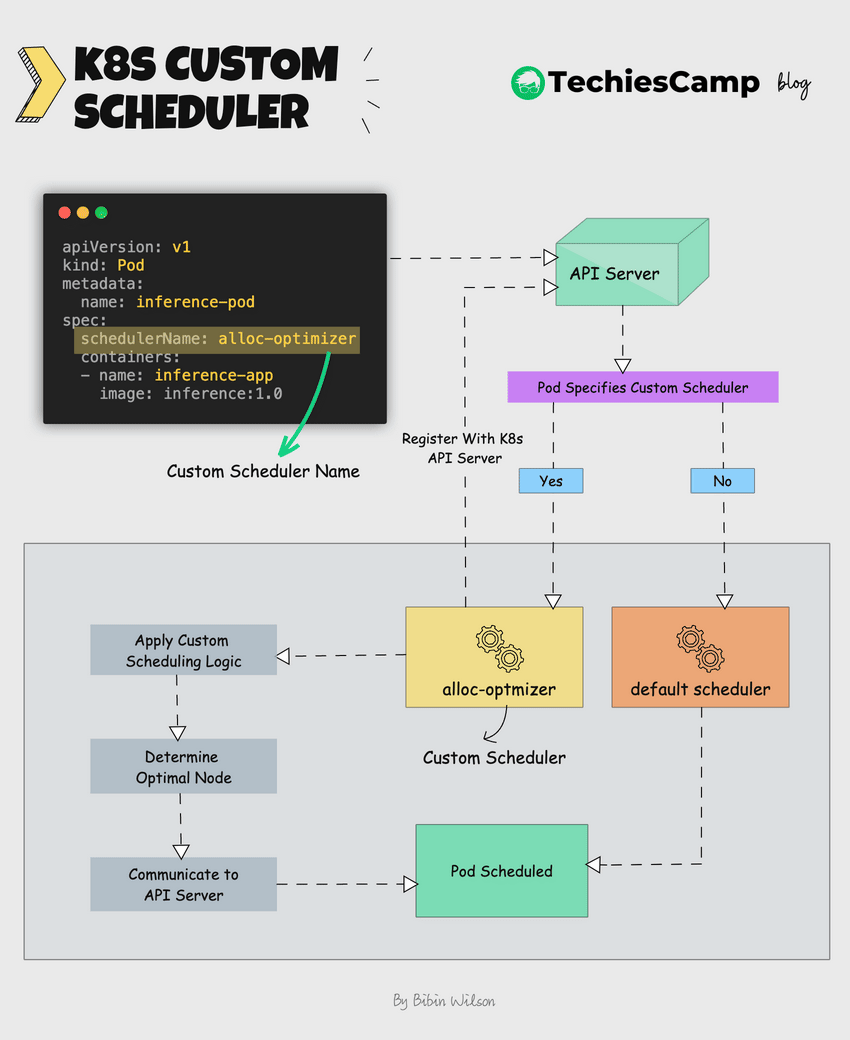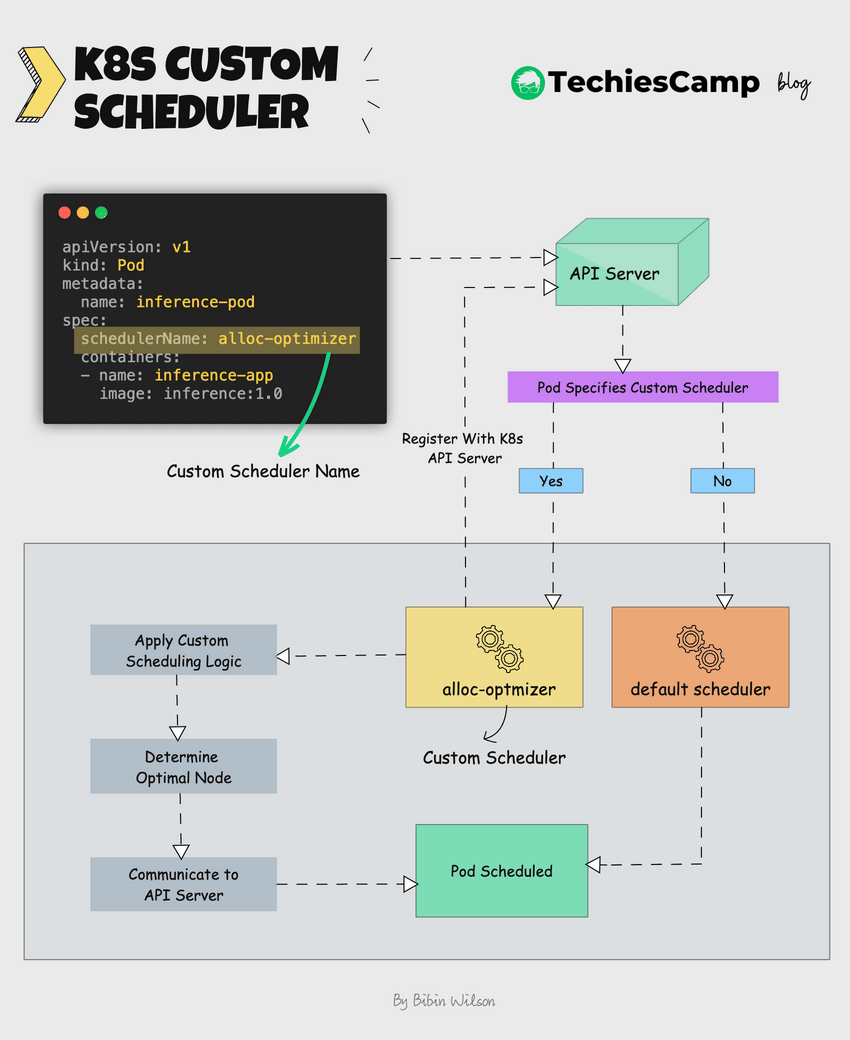
Here's how it works.
- Once deployed, The custom scheduler registers itself with the Kubernetes API server.
- The custom scheduler runs alongside the default scheduler.
- It watches for unscheduled pods that specify the custom scheduler name.
- The custom scheduler can then apply its own logic to determine the optimal node for the pod.
- If the custom scheduler decides on a node, it communicates this decision to Kubernetes.
- It then communicates this decision back to the API server using the Kubernetes scheduling APIs.
- Kubernetes then schedules the pod to the chosen node.
Adding a Custom Scheduler to a Pod
To add a custom scheduler to a pod, you need to specify it in the pod's configuration.
Here's how
Specify the custom scheduler in your pod spec using the schedulerName field:
apiVersion: v1
kind: Pod
metadata:
name: inference-pod
spec:
schedulerName: alloc-pptimizer
containers:
- name: inference-app
image: inference:1.0By specifying alloc-pptimizer in the schedulerName field, you're instructing Kubernetes to use your custom scheduler for this particular pod instead of the default one.
Note: The custom scheduler must be properly configured and running in the cluster before you can use it for scheduling pods.
How many Schedulers can you run in a cluster?
You can run as many custom schedulers as you need alongside the default scheduler.
Each custom scheduler runs as a separate deployment in the cluster.
For example , lets say there are two custom schedulers.
- The Default Scheduler handles general workloads.
- Custom scheduler 1 manages batch jobs or high-performance computing tasks.
- Custom scheduler 2 handles workloads with specific hardware requirements, like GPUs and uses
MostAllocatedstrategy to save costs.